RANRAC: Robust Neural Scene Representations via Random Ray Consensus ECCV 2024
-
Benno Buschmann
TU Delft -
Andreea Dogaru
FAU Erlangen-Nürnberg -
Elmar Eisemann
TU Delft -
Michael Weinmann
TU Delft -
Bernhard Egger
FAU Erlangen-Nürnberg


Video
Abstract
Learning-based scene representations such as neural radiance fields or light field networks, that rely on fitting a scene model to image observations, commonly encounter challenges in the presence of inconsistencies within the images caused by occlusions, inaccurately estimated camera parameters or effects like lens flare. To address this challenge, we introduce RANdom RAy Consensus (RANRAC), an efficient approach to eliminate the effect of inconsistent data, thereby taking inspiration from classical RANSAC based outlier detection for model fitting. In contrast to the down-weighting of the effect of outliers based on robust loss formulations, our approach reliably detects and excludes inconsistent perspectives, resulting in clean images without floating artifacts. For this purpose, we formulate a fuzzy adaption of the RANSAC paradigm, enabling its application to large scale models. We interpret the minimal number of samples to determine the model parameters as a tunable hyperparameter, investigate the generation of hypotheses with data-driven models, and analyse the validation of hypotheses in noisy environments. We demonstrate the compatibility and potential of our solution for both photo-realistic robust multi-view reconstruction from real-world images based on neural radiance fields and for single-shot reconstruction based on light-field networks. In particular, the results indicate significant improvements compared to state-of-the-art robust methods for novel-view synthesis on both synthetic and captured scenes with various inconsistencies including occlusions, noisy camera pose estimates, and unfocused perspectives. The results further indicate significant improvements for single-shot reconstruction from occluded images.
Pipeline
Overview of our robust reconstruction pipeline with RANRAC applied to light field networks [Sitzmann 2021].
The RANRAC algorithm for LFNs samples random hypotheses by selecting a set of random samples from the given perspective (a), and inferring the latent representation of these rays using the autodecoder of a pretrained LFN (b). The obtained light field is then used to predict an image from the input perspective (c). Based on this prediction, confidence in the random hypothesis is evaluated via the Euclidean distance between the predicted ray colors and the remaining color samples of the input image. The amount of samples which are explained by each hypothesis up to some margin are used to determine the best hypothesis (d). All samples explained by the selected hypothesis are used for a final inference with the LFN to obtain the final model and latent representation (e).
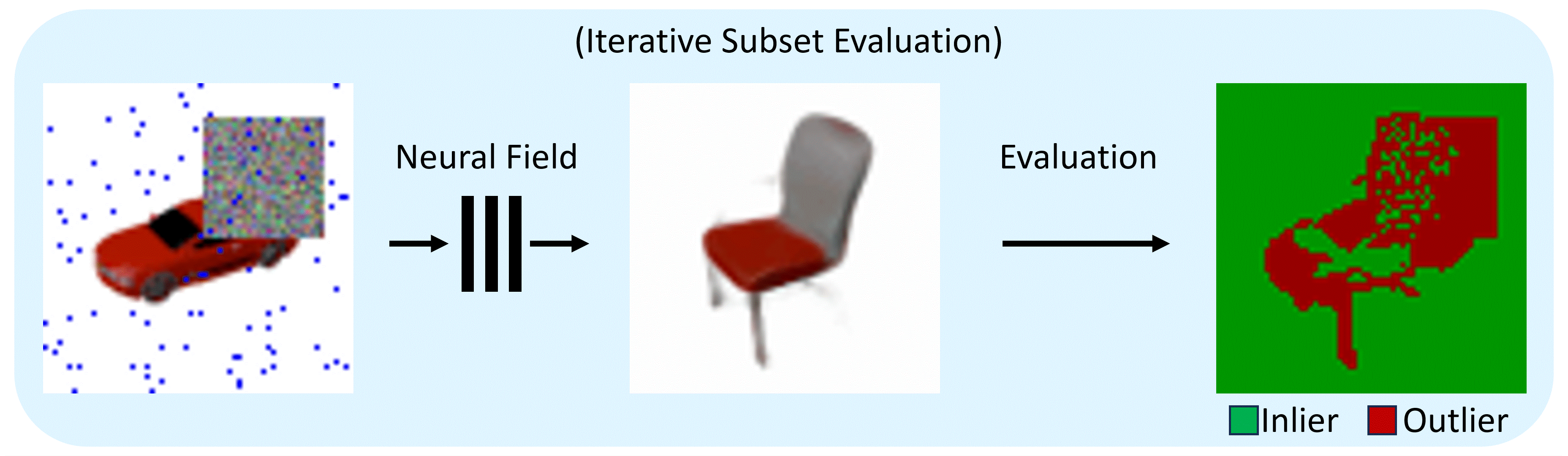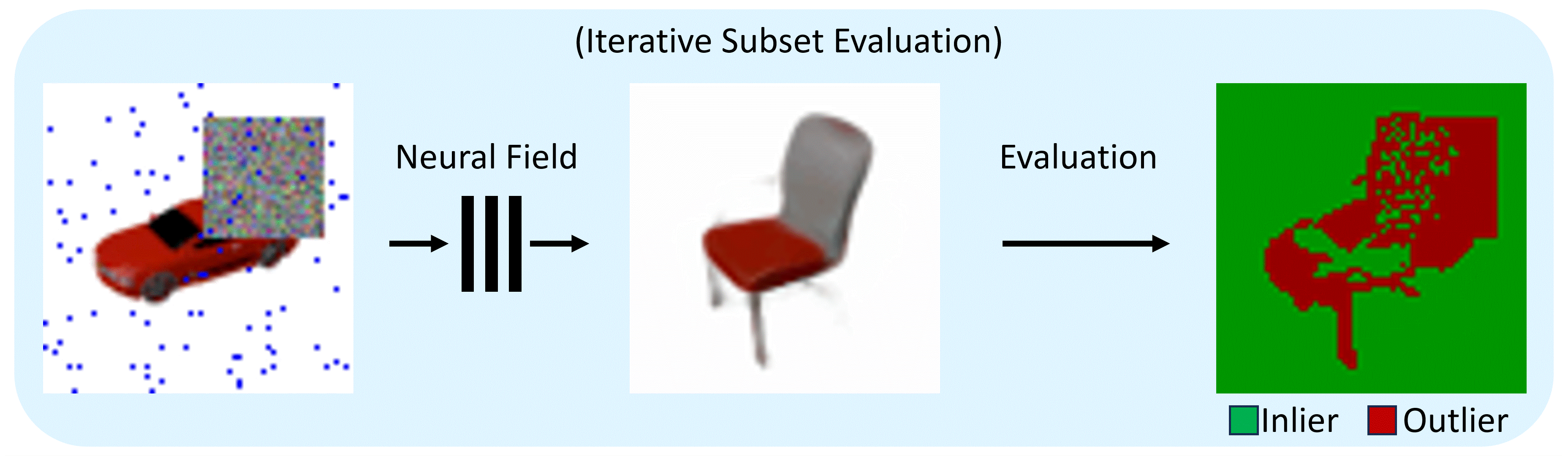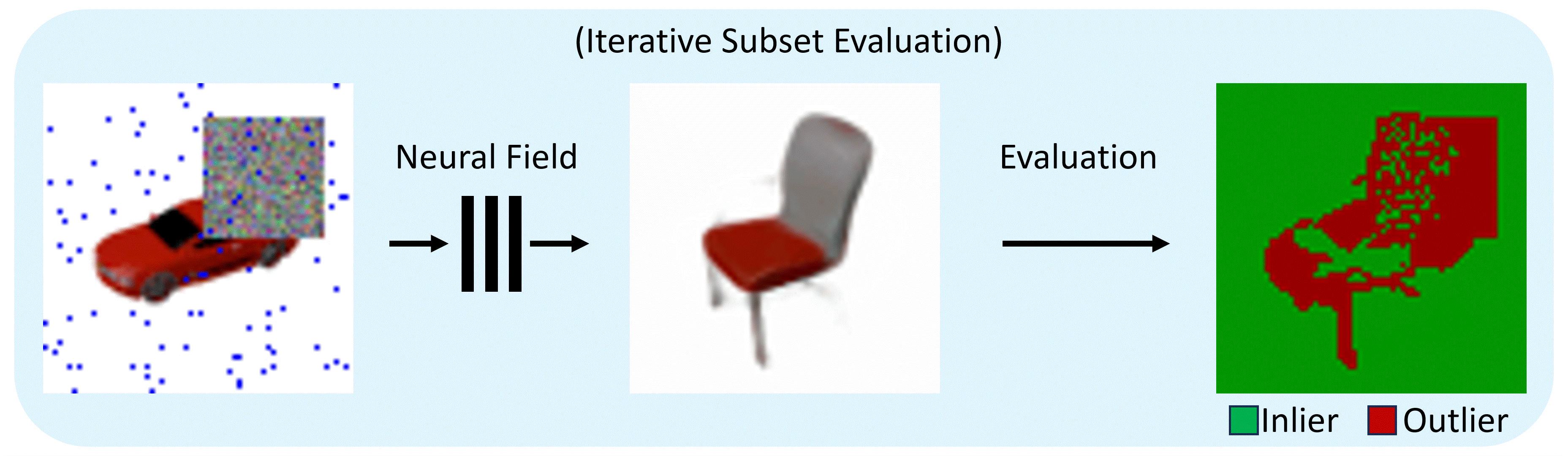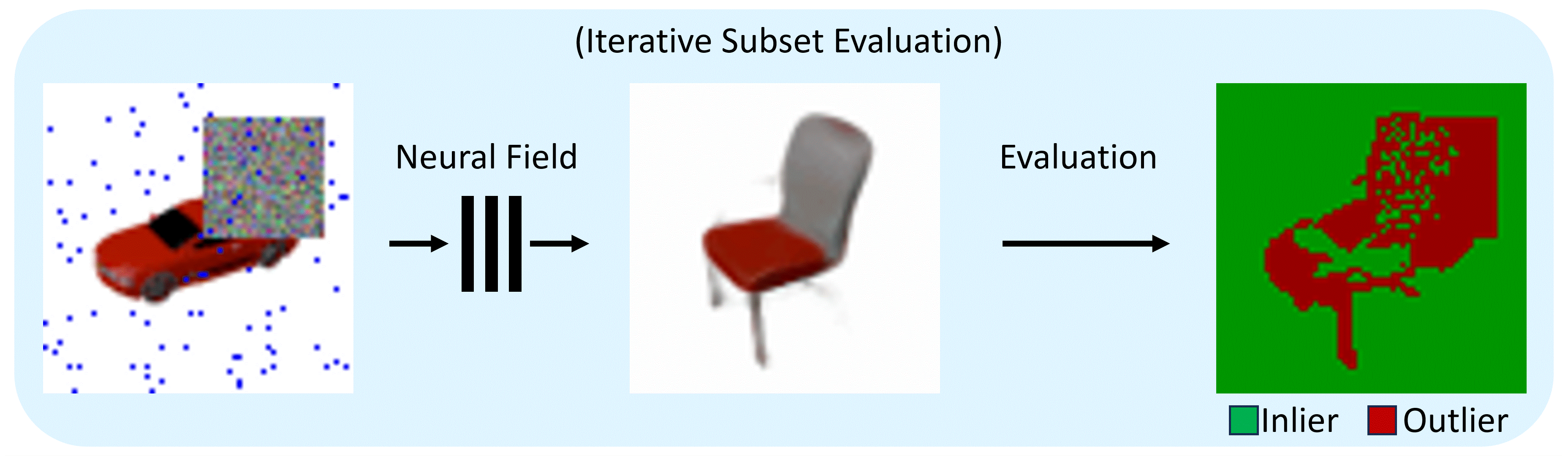
For the application to Neural Radiance Fields, enabling photo-realistic reconstruction from real-world data, the pipeline is adapted: The sampling takes place in image space and the evaluation becomes a two-step process.
RANRAC applied to Light Field Networks
With the application of RANRAC to light field networks [Sitzmann 2021] we enable reconstruction from a single occluded input perspective.
| Occlusion | Input | LFN | RANRAC (Ours) | Ground Truth | Consensus Set |
|---|---|---|---|---|---|
| 0% |  |
 |
 |
 |
 |
| 5% |  |
 |
 |
 |
 |
| 15% |  |
 |
 |
 |
 |
| 25% |  |
 |
 |
 |
 |
| 35% |  |
 |
 |
 |
 |
| 45% |  |
 |
 |
 |
 |
RANRAC enables single-shot multi-class reconstruction from occluded input perspectives.
| Input | LFN | RANRAC (Ours) | Ground Truth |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
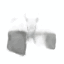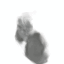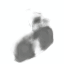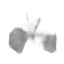 |
 |
 |
RANRAC applied to Neural Radiance Fields
RANRAC removes the artifacts caused by occlusions (left) in NeRF reconstructions [Mildenhall 2020, Müller 2022]. Compared to robustNeRF [Sabour 2023], more details are preserved in the reconstruction (right).


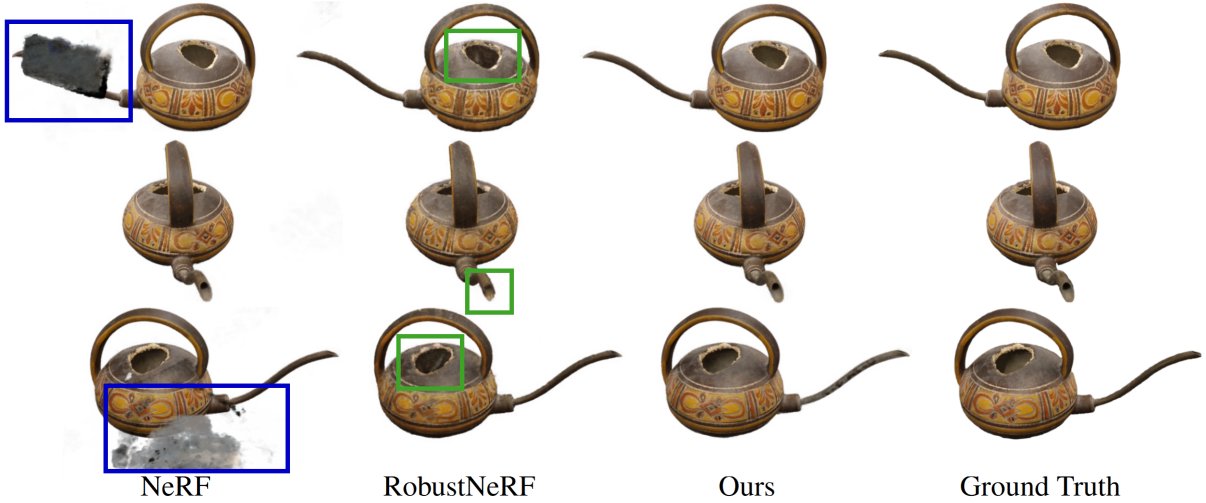
Minor artifacts are best observable when taking a detailed look at individual frames. The inaccuracies RobustNeRF shows compared to RANRAC appear mostly at concavities.
General Robustness of RANRAC
RANRAC is robust to arbitrary sources of inconsistency. Below we compare reconstructions for inconsistent camera parameters. RANRAC removes the artifacts caused by the inconsistencies in NeRF reconstructions [Mildenhall 2020, Müller 2022]. Compared to robustNeRF [Sabour 2023], more details are preserved in the reconstruction. For better emphasis of the details the slider shows the difference of the reconstructions compared to ground truth (more red = more difference).
Citation
Acknowledgements
Benno Buschmann was at FAU funded through a gift by Mitsubishi Electric Research Laboratories (MERL).
Andreea Dogaru was funded by the German Federal Ministry of Education and Research (BMBF), FKZ: 01IS22082 (IRRW).
The authors are responsible for the content of this publication.
The website template was sourced from VET, who adapted from Zip-NeRF, who borrowed from Michaël Gharbi and Ref-NeRF.
Image sliders are from BakedSDF.
References
[Sitzmann 2021] Vincent Sitzmann, Semon Rezchikov, William T. Freeman, Joshua B. Tenenbaum, and Fredo Durand. "Light Field Networks: Neural Scene Representations with Single-Evaluation Rendering." NeurIPS (2021)
[Sabour 2023] Sara Sabour, Suhani Vora, Daniel Duckworth, Ivan Krasin, David J. Fleet, and Andrea Tagliasacchi. "RobustNeRF: Ignoring Distractors With Robust Losses." CVPR (2023)
[Mildenhall 2020] Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. "NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis." ECCV (2020)
[Müller 2022] Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. "Instant neural graphics primitives with a multiresolution hash encoding." SIGGRAPH (2022)
[Fischler 1981] Martin A Fischler and Robert C Bolles. "Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography." Communications of the ACM, 24(6):381–395 (1981)